← Tous les tutoriels
Sauvegarde sur Amazon S3 avec Iperius
Iperius Backup est un logiciel avancé de protection des données doté de nombreuses fonctionnalités. Parmi les destinations de sauvegarde disponibles, il inclut également le célèbre service cloud Amazon S3.
En plus de la sauvegarde sur Amazon S3, Iperius prend en charge les principaux services de stockage en ligne tels que Google Drive, OneDrive, Azure Storage, Dropbox et tout service de stockage cloud compatible avec le protocole S3.
Dans ce guide, nous verrons comment effectuer une sauvegarde à distance sur la plateforme Amazon S3 en quelques étapes seulement.
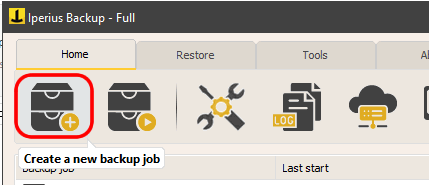
Pour commencer, à partir de la fenêtre principale du programme, créez une nouvelle opération de sauvegarde :
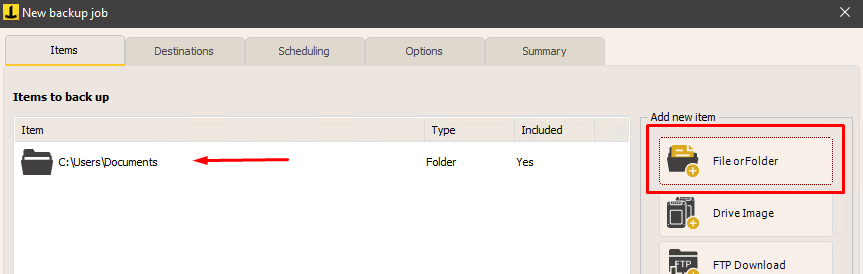
Sélectionnez les dossiers et fichiers que vous souhaitez sauvegarder sur Amazon S3 :
Pour configurer une destination Amazon S3 dans Iperius, vous devez disposer d’un compte Amazon et obtenir les informations d’identification d’accès S3 via la console de gestion AWS .
Accédez à la console AWS via le lien https://console.aws.amazon.com/s3/ .
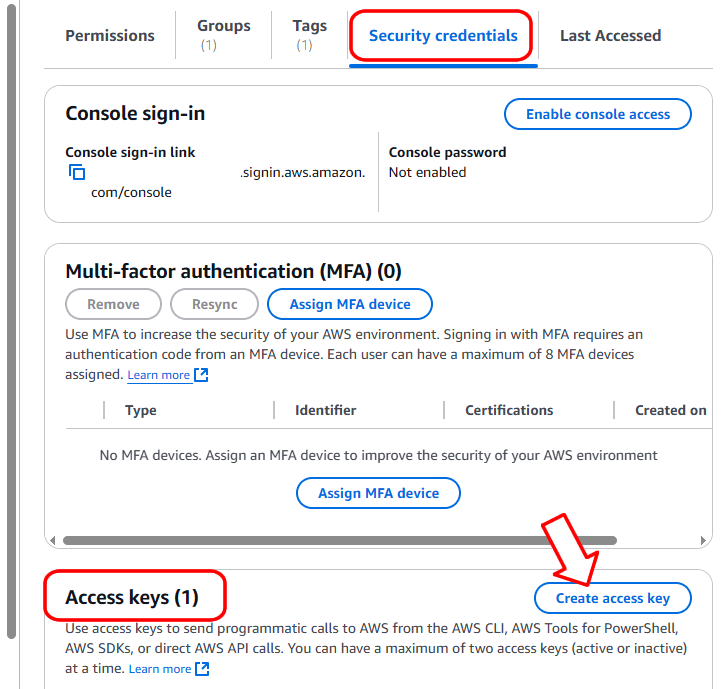
Cliquez sur le nom de votre compte dans le coin supérieur droit, puis cliquez sur l’élément de menu « Informations d’identification de sécurité » :
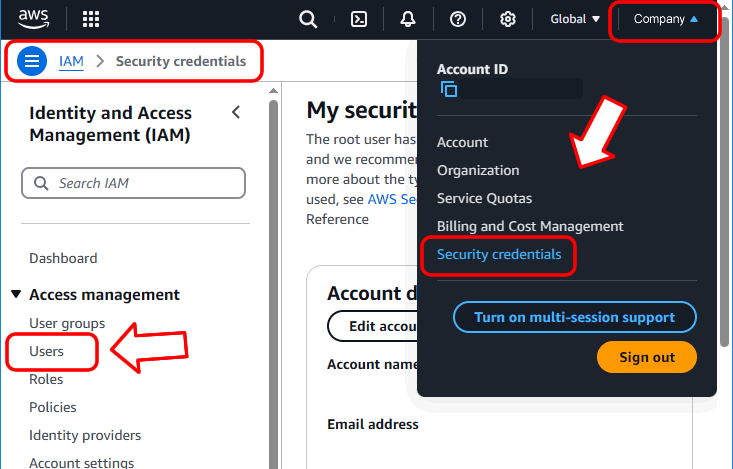
Vous êtes maintenant dans la section IAM (Gestion des identités et des accès). Dans le menu de gauche, cliquez sur « Utilisateurs ».
Ajoutez un nouvel utilisateur en cliquant sur le bouton affiché dans l’image suivante :

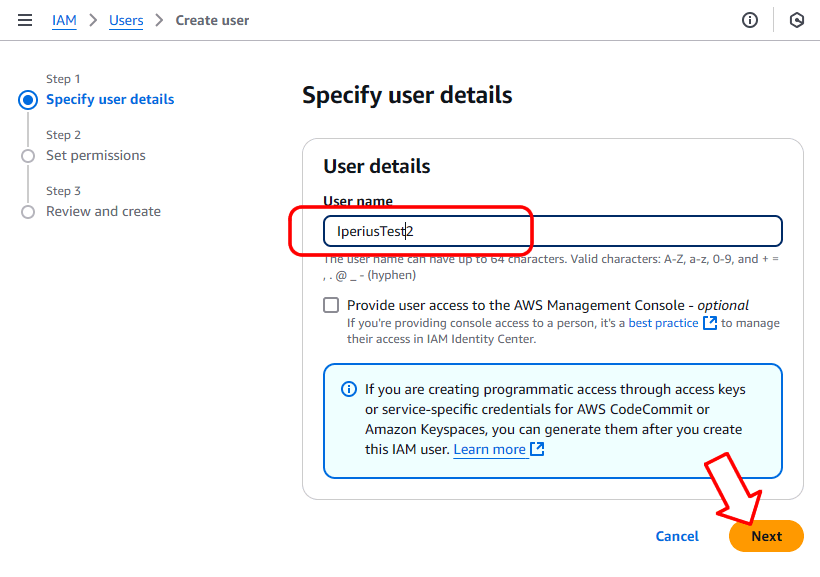
Choisissez un nom pour l’utilisateur et cliquez sur « Suivant » :
Vous devez maintenant ajouter l’utilisateur à un groupe, qui disposera de certaines autorisations d’accès. Sélectionnez « Ajouter un utilisateur au groupe » et créez un nouveau groupe en cliquant sur le bouton approprié, comme illustré ci-dessous :

Choisissez un nom pour le groupe, puis tapez « s3 » dans la zone de recherche et, dans la liste des résultats, cochez la case à côté de « AmazonS3FullAccess ».
Enfin, cliquez sur « Créer un groupe d’utilisateurs » pour créer le groupe.
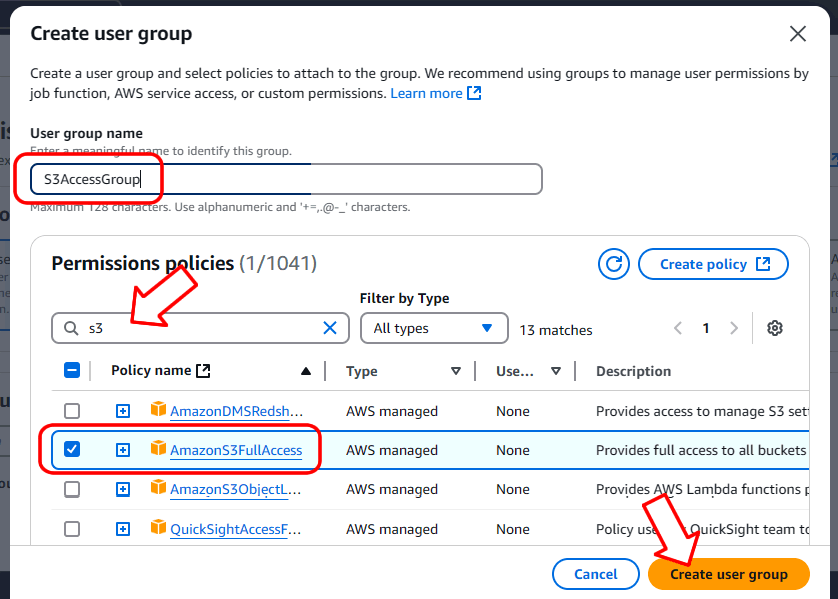
Maintenant que le groupe a été créé, vous pouvez le sélectionner et cliquer sur « Suivant » :
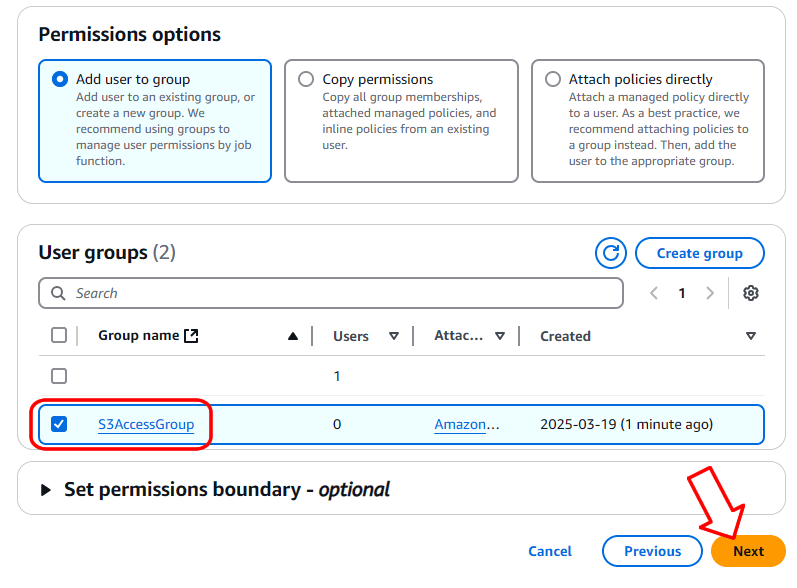
Sur la page de résumé, cliquez sur « Créer un utilisateur » pour créer l’utilisateur :
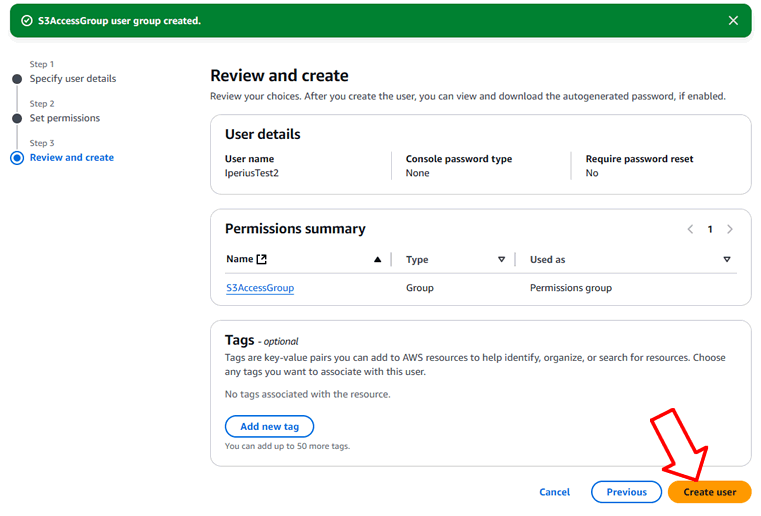
Une fois l’utilisateur créé, cliquez dessus dans la liste pour accéder à ses propriétés et générer les identifiants d’accès S3 :
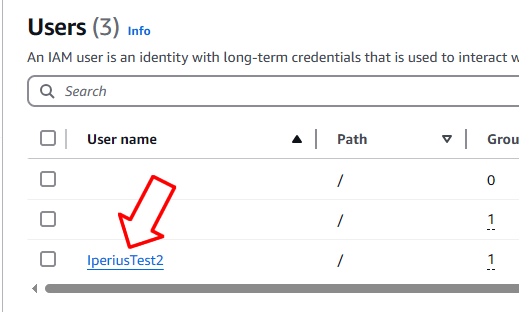
Dans la page des propriétés de l’utilisateur, accédez à la section « Informations d’identification de sécurité » et cliquez sur « Créer une clé d’accès » :
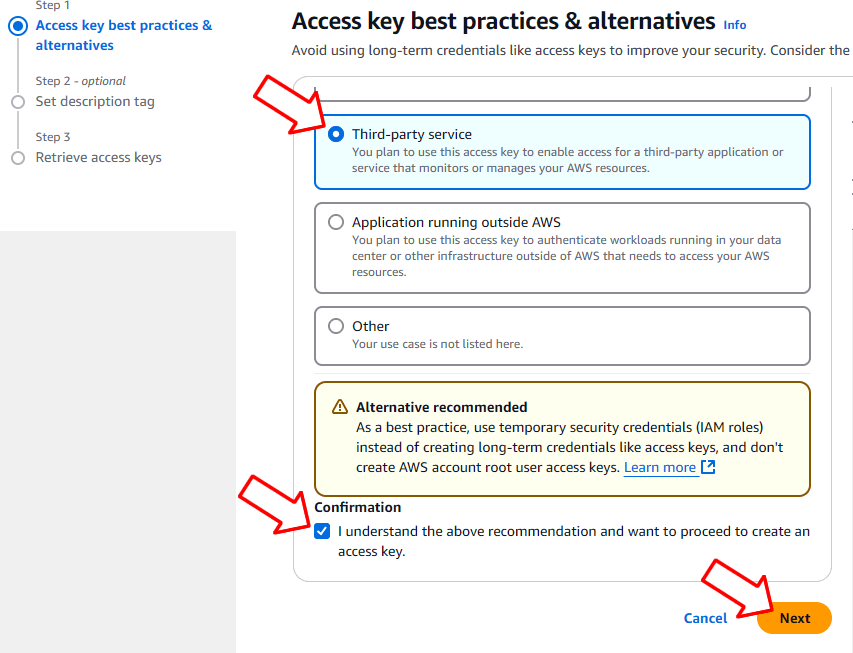
Sur la page suivante, sélectionnez « Service tiers » et cochez la case « Je comprends la recommandation ci-dessus… ». Cliquez ensuite sur « Suivant ».
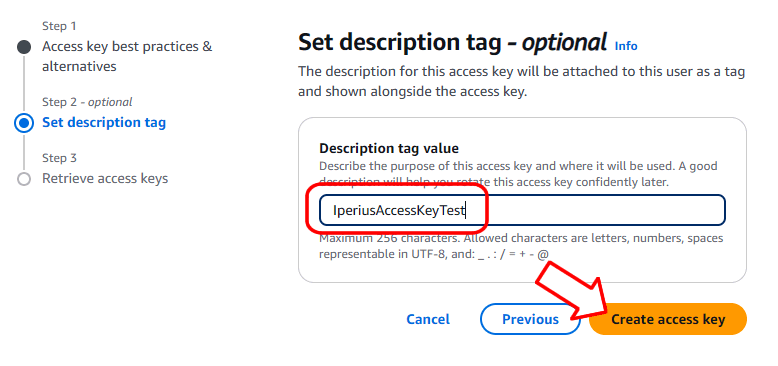
Choisissez un nom pour la clé et cliquez sur « Créer une clé d’accès » :
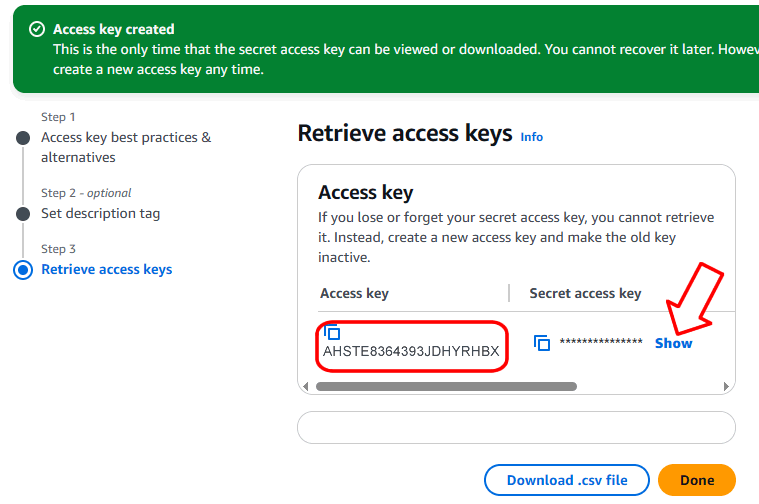
Une fois la clé d’accès générée, vous pouvez consulter et copier les identifiants « Clé d’accès » et « Clé d’accès secrète ». Vous devez le faire maintenant et conserver les identifiants en lieu sûr, car il ne sera plus possible de consulter la « Clé d’accès secrète » après avoir cliqué sur « Terminé » (vous devrez en générer une nouvelle).
Configuration des informations d’identification Amazon S3 dans Iperius Backup
Une fois que vous avez obtenu l’ID de clé d’accès et la clé d’accès secrète, configurez un nouveau compte cloud dans Iperius pour la sauvegarde sur Amazon S3 en ajoutant une destination cloud dans le panneau « Destinations ».
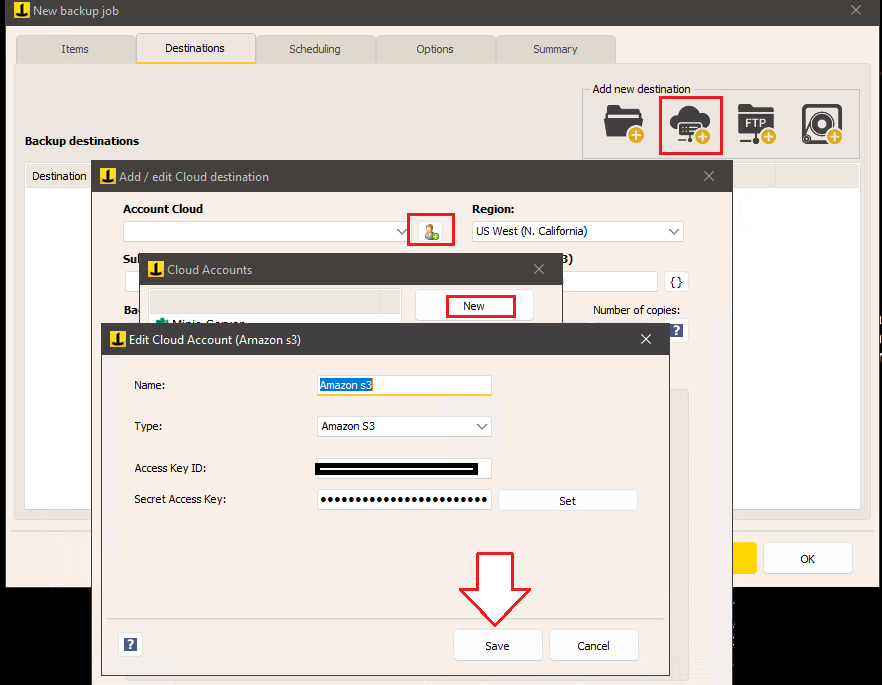
Après avoir créé le compte avec succès, revenez à la fenêtre de configuration de destination, où vous pouvez définir diverses options, telles que le type de sauvegarde ( complète, incrémentielle ou différentielle ), le nombre de copies à conserver, la compression, le cryptage AES avec un mot de passe et les limitations de bande passante.
Il existe deux options particulièrement importantes pour Amazon S3 : la région et le nom du bucket.
La région fait référence à l’emplacement physique réel des serveurs hébergeant vos données et est évidemment très importante pour les performances de sauvegarde. Pour une sécurité et une disponibilité des données extrêmement élevées, vous pouvez également créer plusieurs destinations dans différentes régions. Cependant, pour obtenir les meilleures performances, il est conseillé de choisir la région géographiquement la plus proche de nous.
Le bucket est le conteneur principal des données. Il doit avoir un nom unique à l’échelle mondiale (comme s’il s’agissait d’un nom de domaine) et ne peut pas être dupliqué entre les régions. De plus, il existe des règles assez strictes concernant les caractères que vous pouvez utiliser : https://docs.aws.amazon.com/AmazonS3/latest/userguide/bucketnamingrules.html
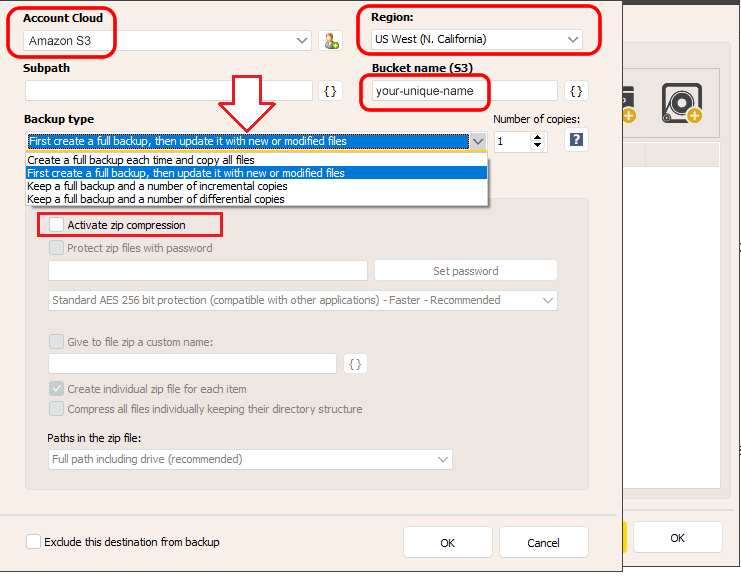
Vous pouvez ensuite configurer la planification des sauvegardes , les notifications par e-mail et d’autres options avancées.
Enfin, attribuez un nom à l’opération et cliquez sur « OK » pour terminer la configuration.
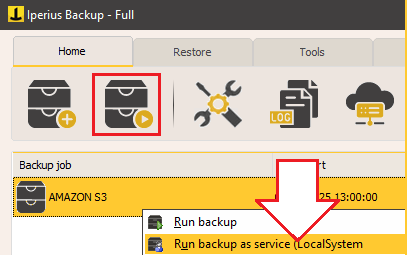
Vous pouvez maintenant démarrer immédiatement l’opération de sauvegarde nouvellement créée en cliquant avec le bouton droit de la souris et en sélectionnant « Exécuter la sauvegarde ».
Grâce à la sauvegarde sur Amazon S3, nous pouvons stocker de manière sécurisée et automatique des sauvegardes de fichiers, de bases de données, de machines virtuelles, de serveurs de messagerie, d’images de disque et de sauvegardes d’organisation Microsoft 365, en les protégeant avec un cryptage AES 256 bits et des connexions HTTPS/TLS.
Pour toute question ou doute concernant ce tutoriel,
Contactez-nous